|
Klassifikation, die gleichzeitige Auswertung von drei und mehr Datensätzen
|
| Merke: Eine digitale Klassifikation ist lediglich eine Interpretationshilfe. Diese Art von Bild-Analyse soll den potenziellen Informationsgehalt des Bildes aufzeigen. Die eigentliche Bild-Interpretation ist eine ganzheitliche Aussage, eine Synthese der Einzelbeobachtungen. Sie sollte sich nicht mit Kleinigkeiten und Einzelbeobachtungen beschäftigen. |
Zuerst die leichter verständliche digitale überwachte Klassifikation.
Hier bringt der Bildbearbeiter zuerst seine eigene subjektive Ortskenntnis zu einzelnen Trainingsflächen ein, die Software sucht dann über Rechenverfahren nach gleichartigen Flächen im Bild.
(Bei der unüberwachten Klassifikation ist es umgekehrt!)
Die Vorgehensweise:
a) Man sucht sich im Satellitenbild größere auffallende Flächen, sog. Test-, Referenz- oder Trainingsflächen.
b) Zu diesen Flächen besorgt man sich durch Begehung (Kartierung, Beschreibung, Fotos), aus der Literatur und aus Spezialkarten oder von ortskundigen Personen (Befragung von Bauern) möglichst genaue und vielseitige Informationen.
c) Mit "Satlupe" oder "Landsat, rechtes Programm" öffnet man einen Datensatz (beim Satelliten Landsat sind es die Kanäle 1 mit 7), man wählt ein möglichst aussagekräftiges Komposit,
dann geht man zu "1. EINGABE", damit erscheint ein eigener Bildschirm:
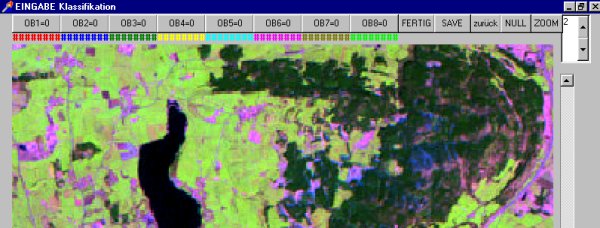
Maximal 8 Objekte können klassifiziert werden. Dazu klickt man zuerst in der Kopfzeile das Farb-Objekt an, das man bearbeiten möchte. Dunkelgrün für Wald, das ist Objekt 3. In der späteren Karte zur Klassifizierung erscheinen dann die Wälder grün. Nun klickt man auf die Referenzflächen zu "Wald" und sammelt Pixel, die sicher in den Referenzflächen liegen. Die gesammelte Zahl wird oben angezeigt. Es können auch mehrere Testflächen zum gleichen Farb-Objekt aufgenommen werden. In welchem Bild man die Pixel sammelt ist gleichgültig. Wenn ein Objekt fertig ist, dann "Fertig" drücken, damit wird die Statistik erstellt: Lage jedes Pixels, Wert für Kanal 1, Wert für Kanal 2, Wert für Kanal 3, usw.
Wenn alle Referenzflächen als Pixel eingegeben sind, dann zurück auf den Hauptbildschirm.
Hier kann man sich bei "2.STATISTIK" das Arbeitsergebnis ansehen.
Die Schwellenwerte für die "Ähnlichkeit"
der Pixel-Profile können hier verändert werden.
Klickt man z.B. auf "Quad" dann erhält man eine Klassifikation. Beim Klick auf "4.Ergebnisse" wird die zugehörige Legende angezeigt.
Nach dieser Klassifikation käme dann die Interpretation der Zusammenhänge, die die Verteilung der Pixel erklärt.
Eine kurze Anleitung von Herrn Duttke zu seinem Menü mit den überwachten Klassifikationen im neuen Programm "Landsat"
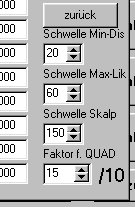
Dies ist das Menü von "Landsat" und rechts sind die Regler für die Schwellenwerte, erreichbar über den Button "2.STATISTIK":

Was macht eine digitale überwachte Klassifizierung eigentlich?
Die zentrale Fragestellung lautet:
Wo sind gleichartige Pixel, die in ihrer Gesamtheit eine Klasse (z.B. Wald der Schadensstufe 2) ergeben?
Durch "1.EINGABE" wurde eine Statistik zu den Pixeln des Referenzgebietes "Schadensstufe 2" angelegt.
Nun entstehen die nächsten Fragen:
Wann sind Pixel gleichartig?
Unter welcher Bedingung sollen sie zu einer Klasse gehören/nicht gehören?
Wie schwierig eine klare Antwort ist, zeigt folgender Versuch in "Satlupe" oder "Landsat, rechtes Programm":
Klicken Sie auf "Klasse 1" und dann auf eine der rechten Farben der angezeigten Palette. Dann klicken Sie auf einen beliebigen Punkt. Alle Pixel mit exakt den gleichen Reflexionswerten in allen Kanälen werden farbig markiert und oben wird deren Anzahl eingeblendet. Sie werden erstaunt sein, wie wenige es sind. Es ist also fast sinnlos, nur "gleiche" Pixel in einer Klasse zu sammeln, man bräuchte für ein Bild zu viele unterschiedliche Klassen, die Unterschiede wären nicht mehr erkennbar.
(Abschließend den Stop-Button anklicken!)
Ziel einer Klassifikation ist es, zusammenhängende Klassifizierungsflächen zu bekommen. Von einer Karte erwartet man Flächen und keine
chaotisch wirkenden Punktemuster. Die räumliche Nachbarschaft spielt also eine sehr große Rolle.
Ein
See oder ein Wald muss aus Pixeln mit ähnlichen Spektralwerten
aufgebaut sein, damit er als "Klasse" mit Namen "See"
oder "Wald" erkennbar ist.
Gleichartige Pixel in gegenseitiger
Nachbarschaft sind auch eine Bestätigung der Zuverlässigkeit
des Sensor-Mess-Systems. Da bei einer Auflösung von 30
m Mischpixel überwiegen, ist eine sprungshafte Änderung
von Einzelwerten nicht zu erwarten, weil es dies in der Landschaft
auch nicht gibt. Sprungshafte Änderungen vor allem von
Zeile zu Zeile zeigen Messfehler der Sensoren an.
Hierzu
ein kleines Experiment: Lade Kanal 3 in PSP und schneide 30
mal 30 Pixel große Bilder immer genau um 1 Pixel versetzt
aus und vergleiche im Histaogrammfenster die ausgeschnittenen
Einzelbilder. Wie stark ändert sich das Histogramm hinsichtlich
Kurvenverlauf und Mittelwert?
Wie könnte man eine Klassifizierung mit
traditionellen Arbeitstechniken durchführen?
Man geht
ins Gelände (See, Moor) und misst an einzelnen Punkten
die Spektralwerte mit einem Spektrometer. Man trägt die
Werte in ein Diagramm ein und verbindet schließlich die
Messwerte je eines Geländepunktes (Px) durch einen Kurvenzug.
(Excel-Anwendung)
Ein Kurvenzug (Reflexionsprofil) der Mittelwerte
charakterisiert dann den See oder das Moor.
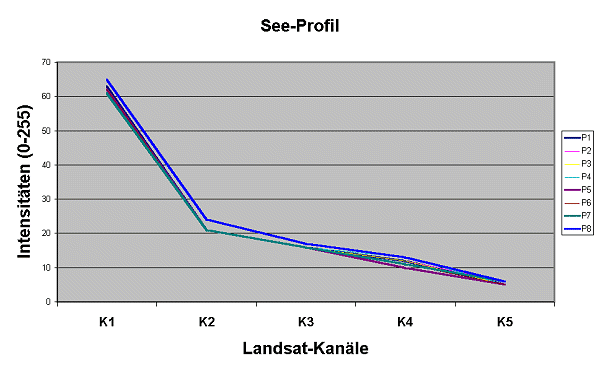
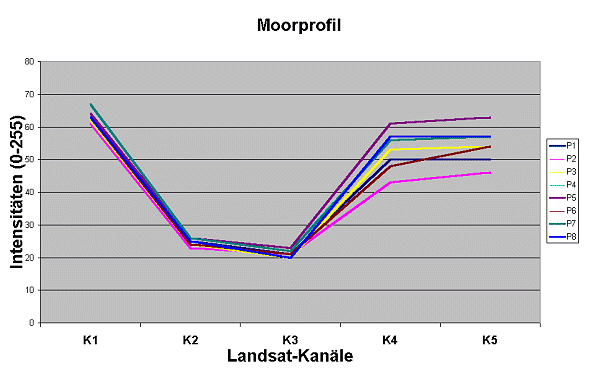
Nach dem Diagramm lässt sich entscheiden,
wann ein Geländepunkt (Referenzpixel) typisch für
"See" oder "Moor" ist und wann nicht.
Für
das Rechenverfahren bedeutet dies:
Alle Pixel, die sich von einem Referenzpixel nur in bis zu 2 (oder x) Intensitätsstufen in jeweils allen Sensorkanälen unterscheiden, gehören zur Referenzklasse. In der Natur sind ähnliche Erscheinungen oft dicht nebeneinander, sodass eine flächendeckende Pixelmenge für die Klasse zu erwarten ist.
Probleme:
- Konkurrierende Klassen überdecken sich umso stärker, je größer die zugelassene Fehlertoleranz ist. Bei niedriger Fehlertoleranz gibt die Klassifikation aber keine zusammenhängenden Punktmengen.
- Ein weiteres Problem besteht darin, dass sich zwei konkurrierende Klassen nur z.B. im NIR wesentlich unterscheiden (Waldschadensstufe 1 oder 2), alle anderen Informationen sind nahezu identisch. Damit kommen flächendeckende Klassen nicht mehr zustande.
Es ergeben sich Unterklassen im Punktemuster. Die Erhöhung
der Fehlertoleranz (Schwellenwerte) verbindet die Unterklassen
zu einer Klasse.
Die Beispiele "See" und "Moor" unterscheiden sich im blauen Kanal (K1) fast nicht, im infraroten Bereich aber sehr deutlich. Dies ist hier gerade der Vorteil, um Wasser und Moorflächen voneinander trennen zu können.
Es gibt viele Klassifizierungsmodelle. In der Praxis wird das Auswahlproblem recht einfach gelöst. Man nimmt das Verfahren, das für die Testgebiete das beste Ergebnis liefert. Die Software "Landsat" bietet vier verschiedene Verfahren an. Die Maximum-Likelihood-Methode wird in der Wissenschaft am häufigsten eingesetzt.
Wenn man dieses Verfahren verwenden möchte, so ist ein geeigneter Schwellenwert unter dem Menüpunkt "2.STATISTIK" experimentell herauszufinden.
Weiter zu Klassifizierung/Teil 3.
![]()